



前言
最近在尝试用 OpenClaw(原 ClawDBot)做一些长期运行的自动化 / Agent 任务,这里记录一下真实使用体验、踩过的坑,以及我认为它适合和不适合的场景。
这段时间openclaw非常火,它的核心理念是让 AI 真正“驻留”在你的设备或私有服务器上,并通过你日常使用的通讯软件(如 WhatsApp, Telegram, Discord, Slack 等)为你提供服务。也就是说,你可以在社交媒体上,像给朋友发消息一样,就能让一个AI帮你做事情。
关于 OpenClaw(原clawdbot)
传统的大语言模型,比如 ChatGPT 或 Claude,通常只能在你呼叫它时才执行任务,它们本质上还是“静态的对话系统”。而 OpenClaw 的设计理念是让 AI 长期“驻留”在你的设备或服务器上,可以主动工作,而不是被动等待用户发起请求。 这样的架构已经不再是简单的聊天机器人,而是一种 新的“智能自动化代理”范式。在我的理解里,OpenClaw 更像是一个 面向 AI Agent 的自动化运行框架,它解决的不是“模型能力”,而是 “让 Agent 稳定、持续、可运维地跑起来” 这件事。
这里首先列举一些OpenClaw的一些实践,能更加直观感受到它的优势:
- 自动管理邮件、消息与提醒,能自动检查邮箱,清除垃圾邮件,把你邮箱的待办同步到todo,给你总结邮件等。
- 自动化任务与工作流程执行,能定时执行特定的任务,比如“每天早上七点给我总结一下我今天的日程,然后发我”、“每天早上九点给我发送一下今天的时事热点,以及相关解读”。
- 部分用户甚至将 OpenClaw 与智能家居平台(例如 Home Assistant)结合:通过 AI 语义指令控制家庭设备、持久记忆用户习惯、环境状态、基于条件自动执行家居规则。
- 长期持久记忆+自动化策略之行,使其能记住上下文以及工作进度,很高程度上模拟“数字员工”。
快速体验OpenClaw
openclaw支持在多种不同的终端安装部署,但不太放心用在自己电脑上,因此比较好的实践方式是将其部署在云端上,成本不高,安全性可控。同时还有一个公网ip。
tips:目前腾讯轻量云的openclaw镜像,支持很多主流im,如qq、企业微信、飞书、钉钉等(开源版本的没有支持国内的im)
构建方式腾讯云已经给得很全了,可以参考文章
- 选购一台轻量云服务器,安装对应的openclaw的镜像
- 参照教程 https://curl.qcloud.com/bMHN4OIb 快速部署
完成构建以后快速进行体验了下:
由于项目是在服务器中部署,因此我让他帮我总结一下今天的时事热点,并且返回给我可访问的公网连接。
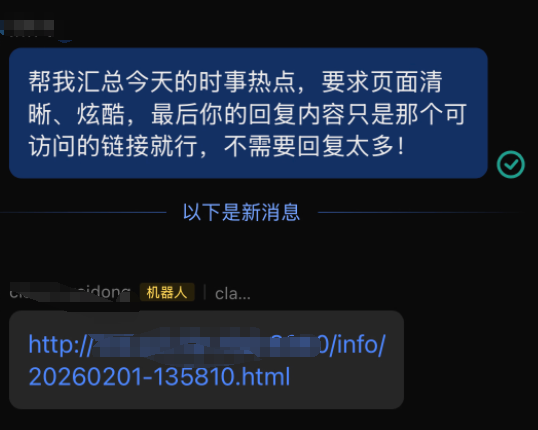
访问公网地址,直接能访问出对应的html页面,整体还是不错的,你甚至可以将其设置为定时任务,让你的「AI员工」,每天给你定时汇报。
OpenClaw 并不是「会看屏幕的 AI」,那它是怎么做到这些自动化的?
看到一些使用案例,很多人的第一反应其实是:
它是不是像人一样“看着屏幕”,然后帮我点按钮、填表单、操作软件?
但事实上,OpenClaw 并不是一个基于视觉的 AI,也不依赖图像识别或鼠标点击来完成操作。
它的核心思路,恰恰相反——
不是“像人一样操作界面”,而是“像程序一样直接控制系统和服务”。
OpenClaw 能完成登录平台、执行任务、发送消息,本质依赖的是三类能力:
程序级的接口调用(API / Web 请求)
对于支持接口的平台,OpenClaw 直接通过 API 完成登录、读取数据和执行操作,这也是最稳定、最推荐的方式。
基于浏览器的自动化控制(而非视觉点击)
对于没有公开 API 的网站,OpenClaw 通过浏览器自动化工具去“控制网页结构本身”,例如填写表单、提交请求,而不是识别屏幕像素或按钮位置。
系统级自动化能力
由于 OpenClaw 是运行在你自己设备或服务器上的守护进程,它可以执行 shell 命令、读写文件、调用脚本,完成一系列传统程序才能做的事情。
这意味着,它并不是一个“模仿人类操作 UI 的机器人”,而是一个真正站在系统层面工作的 AI Agent。
和OpenClaw vs「LLM + MCP 工具」:它的优势到底在哪里?
openClaw 和一个“配置了很多 MCP 工具的大模型”相比,本质差别到底是什么?
现在的 LLM 已经可以通过 MCP / Function Call 调用各种工具,看起来也能“做很多事情”。
LLM + MCP:解决的是「能力问题」
先说 LLM + MCP。
这种模式的核心在于:让模型拥有更多“可调用的能力”。
比如:
- 能不能访问文件
- 能不能调用接口
- 能不能执行某个操作
在这个体系里,模型仍然是被动触发的:
- 你发起一次请求
- 模型根据上下文决定是否调用工具
- 任务完成后,请求结束
从本质上看,它依然是一次性的执行模型:
一次输入 → 一次推理 → 一次执行 → 结束
这在“单次任务”“即时问答”“辅助决策”场景下非常好用,但它并不关心——
任务是否需要持续、状态是否需要保存、失败后如何恢复。
OpenClaw:解决的是「运行与生命周期问题」
而 OpenClaw 关注的,是另一件事:当 AI 不再只是“回答问题”,而是要“长期承担某个角色”时,谁来负责它的运行?
在 OpenClaw 的设计中,模型能力反而不是最重要的部分,它更像是一个被托管的组件。
真正被重点解决的是:
- 进程是否常驻
- 任务是否可以持续执行
- 状态是否可以跨时间保存
- 是否能主动触发而不是被动响应
- 是否具备基本的运维与可控性
也正因为如此,OpenClaw 更像是在为 AI Agent 提供一个运行时(Runtime),而不是单纯扩展模型能力。
直观对比
有一个最直观的例子是,当你问llm+mcp的Agent超出它能力范围的事情的时候,他会提示你它没有这个工具。但是当你问openclaw的时候,他能自己去解决,比如自己写接口,自己去网上找对应的skills,自己去寻找解决你问题的方法,并且落地实践。甚至可以自己给自己安装skills。
也就是说它完全已经是一个站在独立执行问题的超级开放的个体Agent了,不需要依附于任何能力边界。
但它不适合所有场景
举一个最直观的例子:你不可能用 OpenClaw 去直接维护一个复杂项目,或者让它独立完成一整个代码工程。这在现实中其实并不成立。
从本质上看,OpenClaw 更像是一个站在操作系统层面的 AI Agent。
它擅长的是:通过自然语言去调度和控制你的计算机或服务器,而不是在代码的细节层面,像一个资深程序员一样理解并重构你的项目。也就是说,它并不会直接“理解你的业务代码结构,然后帮你改代码”。
它更多扮演的是一个执行者和协调者的角色。
在实际使用中,更合理的方式是:
- 你不让它直接写或修改核心代码
- 而是让它去操作 Git、管理版本、发起 PR、执行构建或测试流程
- 同时,把真正的“写代码”这件事,交给更擅长垂直编程能力的工具或模型(例如 Claude、Gemini 等)
在这个过程中,OpenClaw 的角色更像是:
一个能够下命令、调工具、跑流程的“执行型员工”。
你可以这样理解这个协作关系:
- 你是老板:只给目标,不管细节
- OpenClaw 是你的员工:负责拆解目标、下达指令、协调工具
- 垂直领域工具(代码模型、IDE、CLI 工具):真正完成具体的专业工作
例如,在编程场景下,你可以让 OpenClaw:
- 操作 Git 做版本管理
- 调用代码模型生成或修改代码
- 收集资料、整理信息
- 执行脚本、跑构建、做自动化检查
但它本身并不是那个“写代码的专家”,而是站在更高一层,负责调度和推进事情的人。
简单来说,OpenClaw 现在替代的,更像是你本人在电脑前的操作角色;
而你,则从“亲自敲命令的人”,变成了只需要设定目标、做最终判断的负责人。
个人论坛
https://spssluntan.webboard.org/
https://spssluntan.mybb.online/